
So, I have always enjoyed explaining science to non-scientists. To help everyone understand these things better I want to organize these blogs into a short 1-3 paragraph description of what's new and cool for a fast overview, and a few more paragraphs below to give perhaps more background and details about the news. Please let me know if this works.
What's the short scoop?
Science Journal recently (November 20th 2008) published a report in which the authors show that they can perform "real-time DNA sequencing from a sinlge polymerase molecule". I am thrilled about this report! But why? This technology will make sequencing fast and cheap. For most people, it will be relevant to know that rapid and, in the future, affordable DNA sequencing opens the door for everyone get their own personal genome which can help with diagnosing and fighting diseases like cancer.
However, I am excited about this technology because I think that it will allow us to sequence all microorgansims in excotic environments a lot faster and a lot easier. The DNA from these microorganisms will serve as library of blue prints of building blocks for any given task - especially related to environmental protection? You want an enzyme that breaks down oil from oil spills? Look up what nature came up with! You want to find a better enzyme (protein that makes something happen without getting destroyed) for breaking down cellulose (for biofuels)? Look it up! Why should we reinvent the wheel when nature has provided us with millions of years of engineering expertise. Of course, it's not THAT easy, but the ability to sequence anything cheap and fast will bring us a long way along.
So what is DNA sequencing? Why is it so important?
Every cell in our body and in every other living organism has at some time DNA in it. DNA in our cells acts kind of like a library that contains all the blueprints for everything needed to build and run a new cell. Unlike English, the information is coded in long ladder-like structures (see Figure 1) that contain only 4 different kind of letters on the rungs usually abreviated as A, C, T and G. DNA sequencing means to determine the order of these letters on this string.
 Figure 1. Schematic Picture of DNA taken from the US National Library of Medicine
Figure 1. Schematic Picture of DNA taken from the US National Library of Medicine
Knowing this kind of information can be very useful. Many diseases arise when some of the letters change to something else (called mutation) changing the meaning of a word (or gene in the language of genetics). In some cases, this could tell the cell:"Start dividing and don't stop." This leads to big cell masses that destroy normal healthy cells. We call this cancer. So in a medical sense knowing where these mutations occur and what they are will help scientists and doctors understand what exactly is wrong with our cells and will help them to come up with ways to fix the problem through new drugs or therapies.
So what is the big deal about this feat in biotechnological engineering?
I don't think it would be helpful at this time to completely review the history of DNA sequencing. But if you are interested, you can read a good article about this at Wikipedia. Suffice it to say that previous techniques were indirect observations of sequencing and used to be slow and/or expensive process. The new technique will make sequencing MUCH cheaper because very few reagents are used. The other benefit is that it will be faster - much faster. To give some perspective, it took 10 years for the Human Genome Project to produce a first draft of the human genome using the old technique. According to a recent radio interview with one of the authors, this technology has the potential to resequence the human genome in 1 hour!
Technical Details
 For those interested in more details, I recommend giving the article a read (if you have access). I wanted to find a publicly available image that captures the essence of this technique and found that there is already a wiki article on SMRTS which you can read if you don't have access to the actual article.
For those interested in more details, I recommend giving the article a read (if you have access). I wanted to find a publicly available image that captures the essence of this technique and found that there is already a wiki article on SMRTS which you can read if you don't have access to the actual article.
In short, single molecule sequencing relies on the following main innovations:
1.) To detect fluorescence of one single molecule, detection techniques had to be improved.
2.) Because the DNA synthesis rate of each polymerase is variable, it is essential to observe the activity of each polymerase on its own as otherwise the signal would appear fudged and would not be interpretable. Technologies had to be invented to be able to attach just one polymerase in one read out plate. They call this nanotechnological innovation zero-mode waveguide (ZMW) which I understand as making tiny wholes that are closer together than the wavelength of a given light used to scan for polymerase activity. It's basically one way that they try to address the challenge of putting only one polymerase in a whole so they can observe the activity of one polymerase.
3.) The fluorescent nucleotide (basic unit such as A, C, T, G) was reengineered in such a way that the florescent dye is not on the base (A, C, T, G) - the way it is done in the traditional ddNTP based techniques - but on the phosphate group that gets cleaved off. The benefit is that nucleotides labeled this way do not interfere with the polymerase in a meaningful way because the label is cleaved off upon incorporation. So in the end, the newly synthesized strand consists of "normal", untagged DNA.
Synopsis: Why I think it's cool.
The oceans, water-streams, soil, air and body are covered with millions of different bacteria that have been doing what they have. For the the most time though we have not been able to learn anything about these communities because typically one needs a lot of DNA from the same species to sequence it. It was expensive and cumbersome. With this technology we can, in the initial stages, take a scoop of ocean water and determine the DNA of all the organisms in that water easily. Doing this we can build a library of all the DNA sequences, cDNA sequences (and thus proteins). Having this information will make it easy for us to find proteins that do a particular function, and do it well for anything. I especially thinking of ways for breaking down waste such as oil, and heavy metals. The potential of use after sequencing are endless!
What's the short scoop?
Science Journal recently (November 20th 2008) published a report in which the authors show that they can perform "real-time DNA sequencing from a sinlge polymerase molecule". I am thrilled about this report! But why? This technology will make sequencing fast and cheap. For most people, it will be relevant to know that rapid and, in the future, affordable DNA sequencing opens the door for everyone get their own personal genome which can help with diagnosing and fighting diseases like cancer.
However, I am excited about this technology because I think that it will allow us to sequence all microorgansims in excotic environments a lot faster and a lot easier. The DNA from these microorganisms will serve as library of blue prints of building blocks for any given task - especially related to environmental protection? You want an enzyme that breaks down oil from oil spills? Look up what nature came up with! You want to find a better enzyme (protein that makes something happen without getting destroyed) for breaking down cellulose (for biofuels)? Look it up! Why should we reinvent the wheel when nature has provided us with millions of years of engineering expertise. Of course, it's not THAT easy, but the ability to sequence anything cheap and fast will bring us a long way along.
So what is DNA sequencing? Why is it so important?
Every cell in our body and in every other living organism has at some time DNA in it. DNA in our cells acts kind of like a library that contains all the blueprints for everything needed to build and run a new cell. Unlike English, the information is coded in long ladder-like structures (see Figure 1) that contain only 4 different kind of letters on the rungs usually abreviated as A, C, T and G. DNA sequencing means to determine the order of these letters on this string.
 Figure 1. Schematic Picture of DNA taken from the US National Library of Medicine
Figure 1. Schematic Picture of DNA taken from the US National Library of MedicineKnowing this kind of information can be very useful. Many diseases arise when some of the letters change to something else (called mutation) changing the meaning of a word (or gene in the language of genetics). In some cases, this could tell the cell:"Start dividing and don't stop." This leads to big cell masses that destroy normal healthy cells. We call this cancer. So in a medical sense knowing where these mutations occur and what they are will help scientists and doctors understand what exactly is wrong with our cells and will help them to come up with ways to fix the problem through new drugs or therapies.
So what is the big deal about this feat in biotechnological engineering?
I don't think it would be helpful at this time to completely review the history of DNA sequencing. But if you are interested, you can read a good article about this at Wikipedia. Suffice it to say that previous techniques were indirect observations of sequencing and used to be slow and/or expensive process. The new technique will make sequencing MUCH cheaper because very few reagents are used. The other benefit is that it will be faster - much faster. To give some perspective, it took 10 years for the Human Genome Project to produce a first draft of the human genome using the old technique. According to a recent radio interview with one of the authors, this technology has the potential to resequence the human genome in 1 hour!
Technical Details
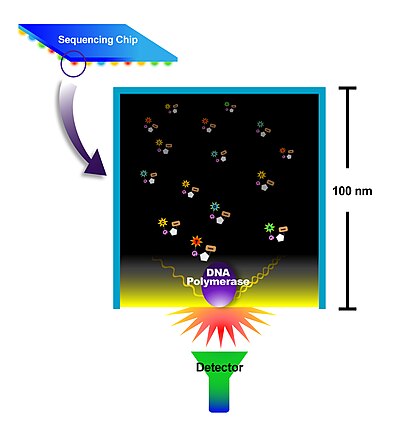 For those interested in more details, I recommend giving the article a read (if you have access). I wanted to find a publicly available image that captures the essence of this technique and found that there is already a wiki article on SMRTS which you can read if you don't have access to the actual article.
For those interested in more details, I recommend giving the article a read (if you have access). I wanted to find a publicly available image that captures the essence of this technique and found that there is already a wiki article on SMRTS which you can read if you don't have access to the actual article.In short, single molecule sequencing relies on the following main innovations:
1.) To detect fluorescence of one single molecule, detection techniques had to be improved.
2.) Because the DNA synthesis rate of each polymerase is variable, it is essential to observe the activity of each polymerase on its own as otherwise the signal would appear fudged and would not be interpretable. Technologies had to be invented to be able to attach just one polymerase in one read out plate. They call this nanotechnological innovation zero-mode waveguide (ZMW) which I understand as making tiny wholes that are closer together than the wavelength of a given light used to scan for polymerase activity. It's basically one way that they try to address the challenge of putting only one polymerase in a whole so they can observe the activity of one polymerase.
3.) The fluorescent nucleotide (basic unit such as A, C, T, G) was reengineered in such a way that the florescent dye is not on the base (A, C, T, G) - the way it is done in the traditional ddNTP based techniques - but on the phosphate group that gets cleaved off. The benefit is that nucleotides labeled this way do not interfere with the polymerase in a meaningful way because the label is cleaved off upon incorporation. So in the end, the newly synthesized strand consists of "normal", untagged DNA.
Synopsis: Why I think it's cool.
The oceans, water-streams, soil, air and body are covered with millions of different bacteria that have been doing what they have. For the the most time though we have not been able to learn anything about these communities because typically one needs a lot of DNA from the same species to sequence it. It was expensive and cumbersome. With this technology we can, in the initial stages, take a scoop of ocean water and determine the DNA of all the organisms in that water easily. Doing this we can build a library of all the DNA sequences, cDNA sequences (and thus proteins). Having this information will make it easy for us to find proteins that do a particular function, and do it well for anything. I especially thinking of ways for breaking down waste such as oil, and heavy metals. The potential of use after sequencing are endless!
Nice details :) Keep up the nice work
ReplyDelete